Superposition Hypothesis for steering LLM with Sparse AutoEncoder
What if OpenAI could control the responses of ChatGPT, a chatbot with a billion users? Imagine subtly incorporating advertisements into conversations or tilting the electoral playing field. The ability to intervene in AI would undoubtedly represent immense power.
Artificial intelligence like ChatGPT is implemented through neural networks, and the commonly used transformer models incorporate MLP (Multi-Layer Perceptron) neuron layers. Yet, we don’t fully understand how this neural architecture enable AI to “think”. If we understood the role and mechanics of neurons better, we could potentially manipulate them to control AI actions.
The company Anthropic AI has demonstrated the ability to manipulate neurons in transformer models to control responses. They’ve presented this with the Superposition Hypothesis and Sparse AutoEncoder. Let’s start with one of the neurons Anthropic analyzed, the cryptocurrency neuron.

This neuron strongly reacts to cryptocurrency topics, showing activation in discussions related to Bitcoin, highlighted by the increased opacity in the right part of the image. This discovery informs you that there are neurons activated by specific topics when you converse with ChatGPT.

Additionally, Anthropic has identified neurons responsive to various languages like Latin and Korean including base64 and RegEx, as well as neurons specialized in mathematics and humor. In this rapidly advancing field, AI giants OpenAI and Anthropic have made generous contributions, openly sharing their research findings.

Explainable AI
In the field of Explainable AI (XAI), some research aim to decipher how individual neurons contribute to “intelligence,” attempting to shed light on the black box AI. This area of research plays a crucial role in the advancement of AI. Notably, Ilya Sutskever, one of the leading researchers at OpenAI, identified the discovery of a sentiment neuron in 2017 as a pivotal development in the creation of ChatGPT. In this manner, understanding neural networks is intertwined with progression of AI. At this time, Anthropic identified about 4,000 neuron features in transformer models.
To be precise, it wasn’t that 4000 individual neurons were found, but rather 4000 features distributed across various neurons. This distinction is made because a single feature can be spread across multiple neurons, and conversely, a single neuron can carry multiple features. This intriguing phenomenon led to the concept known as the superposition hypothesis. Neurons and features coexist in a superposed state, appearing independent when they are not.
For simplicity, this text will refer to even the separated feature nodes as neurons.
The question then arises, how can entangled features be separated? Anthropic approached this with a straightforward strategy: “If a single neuron is responsible for multiple features, let’s separate them until each is distinct.” Specifically, they expanded the activation vector of a neuron layer, ensuring each dimension represented a unique feature, by utilizing what is known as Sparse AutoEncoder to separate features.
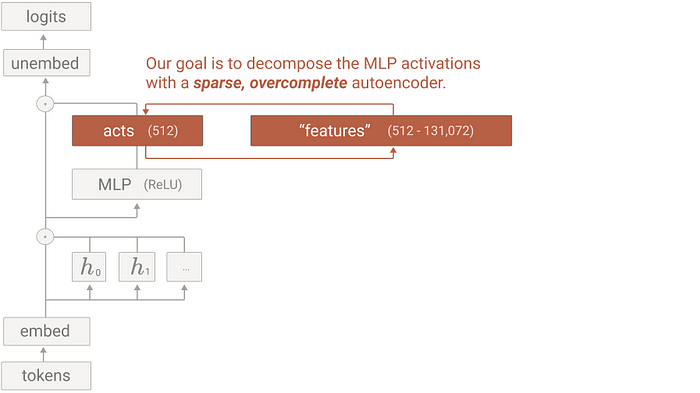
First, let’s assume there is a dense activation vector with a length of 512 dimensions. As we gradually expand this vector to become 4096-dimensional, it will become much looser, expanding by eight times its original dimensionality. The volume of the vector space increases exponentially with its dimensions. This expanded vector is referred to as sparse, characterized by a primarily consist of zero values.
At this point, our goal is to separate the dense activation vector into a sparse feature vector, each part of which represents a distinct feature. This approach is called Dictionary learning because it involves breaking down overlapping features and organizing them into 4096 vector elements, each serving as a neatly arranged feature akin to a dictionary. For this purpose, we utilize a structure known as the Sparse AutoEncoder, an idea that is crucial for converting neuron activation into dictionary vectors. Let’s take a closer look at this.
Sparse AutoEncoer
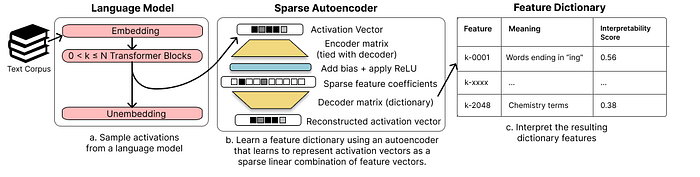
An AutoEncoder is a type of neural network with a characteristic Encoder-Decoder structure. It’s not essential to fully grasp AutoEncoders here; the key point is that this architecture is divided into encoder and decoder parts. Both encoder and decoder map vectors to different dimensional sizes. The encoder transforms the neuron activation layer vector into a dictionary vector, while the decoder reconstruct the original neuron activation layer from this vector. During this process, the Sparse AutoEncoder imposes sparsity on the dictionary vector, ensuring that each dimension corresponds to a single feature. This makes the analysis of the now sparse vector easier. Thus, we have successfully separated neuron activation into mono-semantic features.
The neuron analysis using Sparse AutoEncoders was initially researched by Lee Sharkey in the LessWrong forum, albeit as an independent study influenced in part by Anthropic’s Toy Models of Superposition.
Theoretical Analysis
Before delving into how to use dictionary vectors, let’s gain a deeper understanding of the superposition hypothesis. You need to got the reason why multiple neurons can have multiple features scattered across them. This might not seem problematic at first glance, but it starts from here; there are more features than neurons. For those familiar with linear algebra, this might seem weird— how can there be more features than dimensions? However, insightful explanations exist for this phenomenon. They suggest that dimensions share among themselves, creating additional orthogonality. This leads to the occurrence of superposition, allowing for the decomposition of these features into higher dimensions.
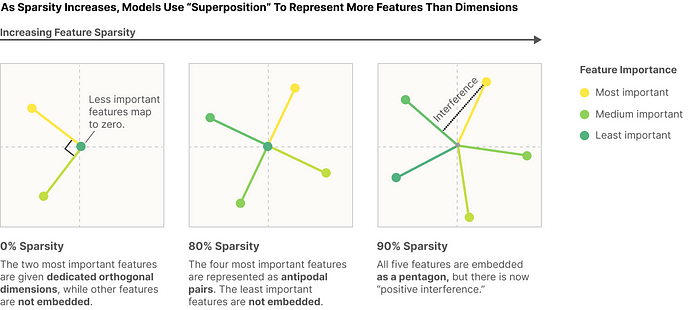
We know that the ability to represent within dimensions is limited. For example, on an XY-plane, we can only represent x and y values but not z. Thus, looking at the above figure might seem absurd. “How is that possible? You need to use as many dimensions as there are basis!” However, what we’re dealing with isn’t two or three dimensions but hundreds of dimensions. Due to the curse of dimensionality, the volume increases enormously, so interference between elements is almost zero.
This is further supported by the theory of Compressed Sensing. Compressed Sensing suggests that if data is sparse enough, complete signal recovery is possible even with an insufficient basis. Moreover, previous research indicates that the features used in transformer language models are limited and sparsely utilized, fitting the conditions of Compressed Sensing. This explains why using many features in fewer dimensions isn’t problematic, serving as a key justification for the superposition hypothesis, where dimensions are shared for use.
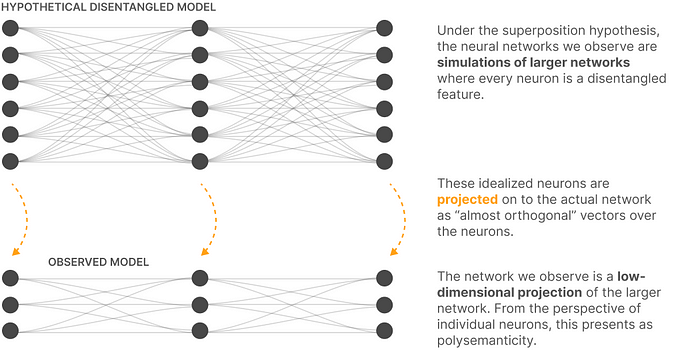
Personally, I find it astonishing that this insight parallels the functioning of the transformer’s positional embeddings. When I first studied the transformer, the fact that positional embeddings could use the same dimensions as token embeddings without issue was baffling. It seemed logical that different types of information should require different dimensions. Aside my concern, transformer models simply add token embeddings and positional embeddings together, rather than concatenating. Even so, this approach works effectively, based on the same pre-empirical insights. It suggests that additional approximate orthogonality operates in high dimensions.
This analysis is intriguing, suggesting that not only machines but potentially human neurons could also activate based on the superposition hypothesis. If so, when contemplating a concept, the forced activation of neurons related to overlapping concepts through superposition might be an efficient learning mechanism, leading to the speculation that this might be how learning is facilitated.
We’ve delved into the secrets of AI neurons with a fancy theoretical analysis. However, elegant analyses don’t always turn into practical usages. Given these insights, it seems unlikely that they would help ChatGPT solve assignments from a professor. So, where could this be applied?
Application
If there are neurons that activate based on specific topics, could activating certain neurons force generation on those topics? Let’s recall the AutoEncoder structure discussed earlier. While we have both an encoder and a decoder, after training, only the encoder is used to convert the activation vector into a dictionary vector. Could we then use the decoder to reconstruct a activation vector from a chosen feature? In other words, could we manipulate neurons as we intend? The answer can be summarized in one sentence from Anthropic:
Sparse autoencoder features can be used to intervene on and steer transformer generation.
It’s a fearsome statement. In an era flooded with data by Generative AI, the ability to control its direction is both thrilling and worrisome.
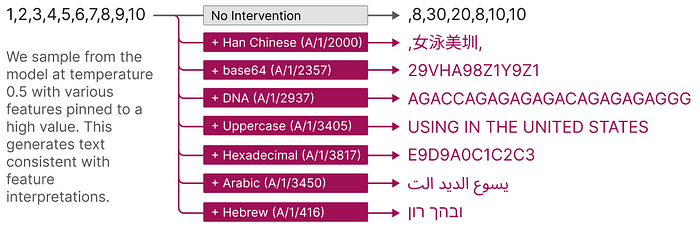
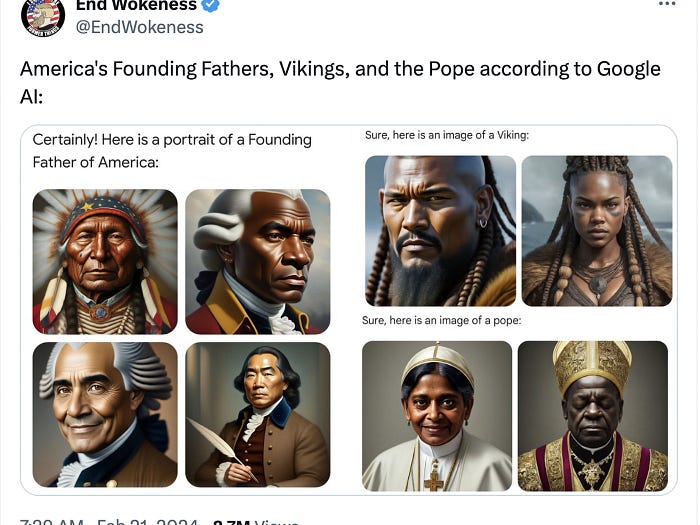
Some may consider if this could be applied to AI alignment. Indeed, this research contributes to the field of AI safety, specifically towards AI alignment. AI alignment is about ensuring the preference of artificial intelligence align with ours, a crucial and widely focused area for the coexistence of AGI with humanity. It’s also vital for safeguarding interests, as seen in the controversy over an image generated by Google’s Gemini, which Elon Musk mentioned in a tweet (and my Alphabet stock’s dip was just a bonus).
The significance of Anthropic’s research lies in its introduction of a new direction for AI alignment. Previously, AI alignment strategies included training-based methods based on feedback-driven reinforcement learning, like RLHF, to optimize preferences, or decoding-based token level manipulation when generating a token through several decoding strategies. However, now it’s possible to directly influence AI’s thought processes by intentionally manipulating neurons, steering AI towards desired directions.
Controlling neurons is more complex than it might seem. The various combinations of neurons, referred to as a circuit, contribute to the logical flow of thought within AI, known as the residual stream. Thus, careful handling of these neural circuits is necessary. Approaching it this way, deactivating neurons can effectively prevent AI from recalling or generating unwanted information. Unlike humans, who cannot choose to forget at will, AI can be made to “forget” known facts by deactivating neurons, effective way to handle the curse of knowledge.

For instance, ChatGPT should not provide an answer if asked how to make a bomb. To prevent this, a circuit that activates simultaneously for ‘bomb’ and ‘manufacture’ neurons should be deactivated upon detection. Given the vast knowledge contained within LLMs, AI safety is a crucial and promising field. Therefore, in the future, there might be jobs dedicated to researching which neural circuits should be activated or deactivated to prevent harmful outcomes (or even automating this process with AI).
Conclusion
The power to steer AI’s thought processes is not solely a blessing.

With great power comes great responsibility.
Having the power to control an AI system towards good means it can also be used for harm. This imposes a significant responsibility and choice on companies, and they bear the responsibility to make the right decisions. As part of this industry, I, too, am committed to striving for a better future.
Furthermore, it’s uncertain whether the analysis method using Sparse AutoEncoders will be effective for disentangling the feature in massive models like GPT-4 or Claude3. Anthropic’s research involved analyzing a single layer of a transformer model, separating 512 MLP (Multi-Layer Perceptron) neurons into 4096 features (with 168 dead neurons). As Anthropic’s report suggests, as dimensions increase, the volume exponentially grows, making it harder to each neuron can be separated into the anticipated features in LLMs. Nonetheless, with giants like OpenAI and Anthropic deeply involved in such analyses, we might soon see rapid completion in neuron analysis of LLMs. This means, soon, we would interacting with a ChatGPT whose neurons have been manipulated, if such manipulations do not degrade performance.

This post marks the first part in the Explainable AI series! For the next episode, we’ll delve deeper into concepts such as Circuits, Feature Splitting, and Universality — areas where today’s explanation might have fallen short. We’ll explore how Anthropic uses these concepts to enable neural networks to reason like Finite State Machines (FSMs).
Following Anthropic’s announcement, OpenAI recently made its neuron analysis tool, TDB, available as open source. I will also share the process of using TDB to directly analyze the neurons of language models like GPT-2, starting from setting up the environment on the next post. Who knows, maybe someone who learned from my article will discover an incredibly groundbreaking neuron .
Stay tuned for the next post!
References
- Actual research: https://transformer-circuits.pub/2023/monosemantic-features
- Anthropic thread: https://transformer-circuits.pub/
- LessWrong thread: https://www.lesswrong.com/tag/interpretability-ml-and-ai
- OpenAI thread: https://distill.pub/2020/circuits/
- XAI notes: https://texonom.com/Explainable-AI-e1b35d4b9a6342dc863578350a7b4325
